 As discussed in Week One, we live in a world of big data, and every day the data grows bigger. From social media posts to online orders to employee databases, the world is being datafied. This datafication has resulted in zettabytes of digital information. The challenge then becomes one of managing the mass of data and creating meaningful information. Data warehouses play an important role in this regard.
As discussed in Week One, we live in a world of big data, and every day the data grows bigger. From social media posts to online orders to employee databases, the world is being datafied. This datafication has resulted in zettabytes of digital information. The challenge then becomes one of managing the mass of data and creating meaningful information. Data warehouses play an important role in this regard.A data warehouse is defined as “an integrated, enterprise-wide collection of high quality information from different databases used to support management decision making and performance management [1].” Data warehouses are commonly found in medium to large organizations across a wide variety of industries. During my employment with a large financial institution, I frequently accessed a data warehouse, particularly the data marts specific to our 78 million customers and prospects.
 One key phrase mentioned in the definition is “high quality information.” A data warehouse is only as good as the information it contains. If the data is not high quality, its use is greatly diminished. Populating data in a data warehouse is done via extraction, transformation, and loading from other databases and data sources. Often these databases are various online transaction processing (OLTP) databases. Data needs to be “cleansed” during the transformation to ensure it is consistent and accurate.
One key phrase mentioned in the definition is “high quality information.” A data warehouse is only as good as the information it contains. If the data is not high quality, its use is greatly diminished. Populating data in a data warehouse is done via extraction, transformation, and loading from other databases and data sources. Often these databases are various online transaction processing (OLTP) databases. Data needs to be “cleansed” during the transformation to ensure it is consistent and accurate.In the case of my company’s customer and prospect data warehouse, data was loaded from a legacy Starbase system (non-relational source of customer transactions), customer relationship management databases, and other related departmental databases. A nightly process would extract and transform the data to ensure it met all the business rules required before loading into the data warehouse.
From an application development standpoint, the data warehouse provided a single, easily accessible source of costumer data that could be leveraged in our group’s applications. Other groups accessed the warehouse for their own purposes, e.g. generating reports, doing analytical analysis and data mining. Often, the information in the data warehouse was referred to as the “single version of the truth.” While many have argued whether it is possible to truly have such truth [2], having a complete and authoritative source of data within an organization is invaluable.
Until I took this Business Intelligence course, I was not familiar with dimensional modeling. An amusing side note is that when I accessed the data warehouse tables, I couldn’t help but notice that they were not normalized. At the time, I assumed this was just laziness on the part of the data warehouse team. Now I understand that the data was dimensionally modeled. A large fact table contained performance measures. Other tables, referred to as dimensions, contained the textual attributes.
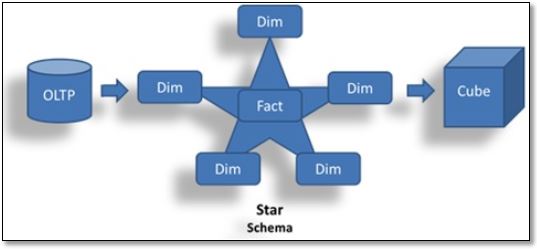 Dimensional modeling is often referred to as a star schema since it can be represented in a star shape with the fact table in the middle and the dimension tables as points of the star. The one-to-many relationship between the dimension and the facts are usually prescribed by creating a numeric, sequential surrogate key. This allows for quicker and more efficient joins and eliminates issues with the natural key changing.
Dimensional modeling is often referred to as a star schema since it can be represented in a star shape with the fact table in the middle and the dimension tables as points of the star. The one-to-many relationship between the dimension and the facts are usually prescribed by creating a numeric, sequential surrogate key. This allows for quicker and more efficient joins and eliminates issues with the natural key changing.Dimensional modeling lends itself to efficient examination of data. The different fact dimensions can be thought of abstractly as a multi-dimensional cube. Analytic processing can be done by slicing the cube, dicing the cube, drilling down, rolling up, and pivoting the cube’s dimensions. Dashboards can be designed to give users an instant snapshot of information that they can act upon. Widgets such as gauges, labels, performance bars, and spark lines can help users quickly visual information.
In total, a data warehouse provides a collection of integral data that can be tapped to produce a virtual fire-hose of information. Data is extracted, transformed and loaded into a dimensional model for optimal performance. Data can then be analyzed as a multi-dimensional cube to efficiently extract salient information. Dashboards can be developed to give instant views into the wealth of information stored in a warehouse.
But given the ubiquitous nature of data warehouses currently, what does the future hold now that Hadoop has stormed onto the scene?
The Future of the Data Warehouse and Hadoop
For over 30 years, organizations have relied on data warehouses in various forms to perform data analysis and make business decisions. In the world of IT, this is nearly a lifetime. John Foley with Forbes succinctly describes why warehouses have such been around for so long: “Data warehouses have had staying power because the concept of a central data repository—fed by dozens or hundreds of databases, applications, and other source systems—continues to be the best, most efficient way for companies to get an enterprise-wide view of their customers, supply chains, sales, and operations [3].”
However, a potential competitor to the data warehouse has recently emerged. “Hadoop is an open-source software framework for storing data and running applications on clusters of commodity hardware [4].” It promises to deliver much of what the data warehouses do, but at a lower cost.

But while Hadoop seeks to challenge the dominance of data warehouses, currently it is generally used to augment the capacity and processing power of the warehouse. As one data professional observed, Hadoop can help “reduce the footprint on expensive relational databases.... That makes our data warehouse platform more affordable and frees up capacity for growth, which in turn makes it look more valuable from an economic perspective [5]."
Indeed, one of the biggest drawbacks of a data warehouse is the cost. Significant infrastructure and personnel resources are required to set up, populate and maintain a warehouse. As big data continues to grow, so do the resources required to support it. This is where Hadoop plays an important role. When budgets are stretched, organizations will look to Hadoop and cloud-based solutions to extend their capacity. This will herald a change in the data warehouse implementation over the next several years, but will not make it obsolete.
As GCN observes, “Instead of a one-size-fits-all approach, organizations will look to tailor their big data volumes to hybrid storage approaches [6].” Consequently, expect Hadoop and similar technologies to complement, not replace, the data warehouse.
References
1. Ram, Sudha. 2013. “MIS 587 -- Data Warehouse Design Cycle.” The University of Arizona.
2. Kelley, Chuck. 2003 December 10. “Data warehouse: The single version of truth.” ITWorld.
http://www.itworld.com/article/2785099/storage/data-warehouse--the-single-version-of-truth.html
3. Foley, John. 2014 March 10. “The Top 10 Trends In Data Warehousing.” Forbes. http://www.forbes.com/sites/oracle/2014/03/10/the-top-10-trends-in-data-warehousing/
4. SAS Institute. “Hadoop: What is it and why does it matter?” http://www.sas.com/en_us/insights/big-data/hadoop.html. Accessed November 12, 2015.
5. Russom, Philip. 2015 January 27. “Can Hadoop Replace a Data Warehouse?” tdwi. https://tdwi.org/articles/2015/01/27/hadoop-replace-data-warehouse.aspx
6. Daconta, Michael. 2014 January 14. “Is Hadoop the death of data warehousing?” GCN. https://gcn.com/blogs/reality-check/2014/01/hadoop-vs-data-warehousing.aspx